Quick Summary
The AI agent lifecycle covers five stages design, development, testing, deployment, and monitoring, and the governance layer connecting them. Based on Accelirate's 2025 enterprise deployments, most agent failures don't happen at launch; they happen between day 30 and day 90, when drift goes undetected. Structuring lifecycle management from day one reduces that risk by over 60%.
AI agents are no longer a proof of concept. They're in production, handling customer queries, processing transactions, managing schedules, and making decisions at machine speed.
But here's the problem most enterprises run into after deploying their first agent is that are well prepared for the launch of agents and not for the longevity.
As a result, an agent that works well on day one can silently drift, misbehave, or become a compliance liability by day 90. Without a structured approach to governing how agents are built, tested, deployed, and retired, that risk compounds fast.
This is what the AI agent lifecycle addresses, and why lifecycle management is quickly becoming one of the most important operational disciplines in enterprise AI.
What Is the AI Agent Lifecycle? (And Why It Matters for Enterprises)
The AI agent lifecycle is the full arc of an AI agent's existence: from the moment a business need is identified to the moment the agent is deployed. It spans ideation, design, development, testing, deployment, ongoing monitoring, and eventual retirement.
It matters because AI agents behave differently from traditional software. A conventional application does exactly what its code tells it to do. An AI agent reasons, interprets intent, selects tools, and produces outputs that vary based on context. That non-determinism is powerful, and it's also what makes unmanaged agents dangerous.
For enterprises looking to reap long-term ROIs from AI Agent, it’s important that they resolve most operational questions like
- Is the agent acting within its intended scope?
- Does it have the right permissions and no more?
- Can its behaviour be tested under real-world variation?
- Can teams detect drift after deployment?
- Can changes in prompts, policies, or tools be traced clearly?
- Can the business trust what the agent is doing in production?
Without right AI lifecycle governance enterprises are risking a bad user experience, you're risking compliance violations, security breaches, and even reputational damage.
What are the five stages of the AI agent lifecycle?
An effective AI Agent Lifecycle involves five key stages, with governance embedded throughout to ensure trust and reliability. Unlike traditional software, enterprises can no longer treat governance as a final checkpoint before release. The decisions that determine whether an agent is trustworthy are made early like in how intent is defined, how guardrails are set, how testing is structured. By the time an agent reaches production, those decisions have already shaped everything that follows. Let’s get into these stages one by one:
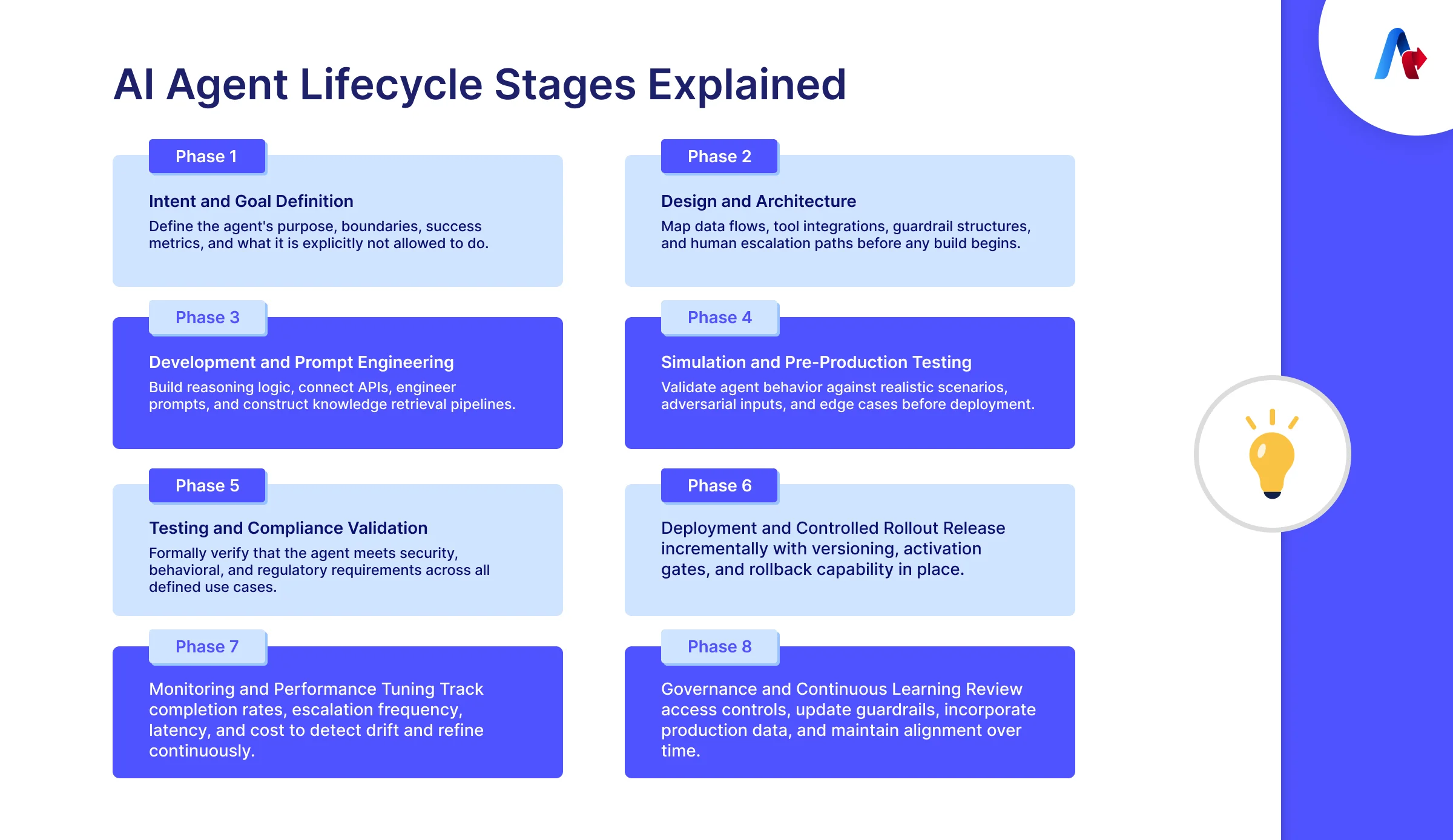
Stage 1. Ideation and Design
This is the initial stage where leaders define what the agent should do, who it serves, what tools it needs, how the success looks like, and where the guardrails sit. This stage sets the ceiling for everything that follows like the code. Underspecified intent here means misaligned behaviour later.
Stage 2. Development
In the second stage developers build the agent's reasoning logic, connect it to tools and APIs, engineer prompts, and construct data pipelines (including RAG pipelines if the agent needs to retrieve knowledge). This is the "inner loop", an iterative cycle of building, testing small, and refining.
Accelirate's AI Agent Activator Program structures this as a 5-week engagement and activation is a formal governance act at the end of Week 4, not a casual go-live. Clients who follow this pattern reduce rollback incidents by roughly half compared to unstructured deployments.
Stage 3. Testing and Validation
Unlike conventional software testing, you’re not only testing whether your agent can produce the right output. You’re ensuring that the agent’s behaviour is consistent within its intended operating conditions, even under hostile conditions. At this point, you need unit testing, scenario testing, and efforts to hack the agent.
Stage 4. Deployment and Release
The agents must be versioned, rolled out through managed rollouts, and activated separately. Activation is an act of governance; that is, the agent is not active unless it is manually activated, making possible some last-minute quality control and quick rollbacks in case of problems.
Stage 5. Monitoring and Tuning
Monitoring and fine tuning is often considered as the last stage of the AI agent lifecycle but often this stage is just the beginning of the outer loop. Which means that in this stage agents are required to constantly monitored examining their effectiveness and efficacy. Like how long it takes to complete tasks, if there are any persistent mistakes and then optimizing the agents accordingly.
In Accelirate-managed programs, agents without defined behavioural baselines at launch showed measurable drift within 45 days in 8 out of 10 cases. This is why establishing what "normal" looks like in the first week after deployment is not optional. Task completion rate, escalation frequency, and latency are the three numbers every team should be tracking from day one. You cannot detect drift without a baseline to compare against.
Ready to build AI agents that stay reliable beyond day 90?
Book a consultation with AccelirateWhat Is AI Agent Lifecycle Management?
AI agent lifecycle management is the governance layer that connects all five stages into a coherent, auditable system.
Without it, each stage operates in a silo. Business teams define intent. Developers build. QA validates. IT deploys. Security monitors. Each team does its job, but no single system connects them, and that gap is exactly where trust erodes.
Here AI agents as accountable digital entities, applying governance standards equivalent to human users, but with controls designed for autonomous behaviour. That includes assigning unique identities to agents before deployment, enforcing least-privilege access, maintaining immutable audit logs, and revoking credentials immediately upon decommissioning.
Effective AI agent lifecycle management closes those seams. It creates continuity from intent through operation, so you can answer basic questions at any point: Is this agent behaving as designed? Has anything drifted? If something goes wrong, what changed and when?
Secure AI Agent Lifecycle: Key Risks and How to Mitigate Them

Most security conversations around AI agents happen too late after deployment, after an incident, or after an audit flags a gap. The reality is that securing the AI agent lifecycle has to start at design, not after the fact. Agents operate autonomously, connect to external tools, and access sensitive data. Here are different ways you can mitigate the risks:
1. Weak intent definition
It needs to be apparent what the agent's scope is. If it isn't, it will be hard to check if it is working appropriately. The agent may appear like it's working, but it's not following the rules of the industry. When purpose isn't clear, is poorly written, or hasn't been into rules that can be enforced, trust can go down.
Mitigation: Before the build starts, provide defined goals, authorized activities, prohibited behaviour, escalation procedures, and criteria for success that can be measured.
2. Too much access
Enterprise agents generally work with a lot of different systems, such as internal applications, external APIs, knowledge bases, and customer data. Security risks go up fast if access is excessively broad, shared, or inadequately recorded. Every agent should have their own digital identity, limited access, provisioning depending on approval, and easy tracking.
Mitigation: To reduce the risk, give each agent a unique identity, apply role-based access restrictions, check permissions often, and take away credentials right away when agents leave or are replaced.
3. Inaccurate build and configuration
If the initial idea is good a planned prompt, a confusing topic, a weak boundary or a bad integration can cause big problems with security and reliability. So, the safe AI agent lifecycle must include planning and setup well as checks when the AI agent is working.
Mitigation: To avoid this, make prompts and instructions short and simple. Set limits on what tools can do. Check that integrations are working correctly. Do not let the AI agent do anything that is not clearly defined.
4. Limited or shallow validation
Having a good test is not enough. AI agents must be tested with requests, unusual situations, mean inputs and situations where they need to say no ask for help or follow strict rules. Validation that is not certain must be part of the AI agent development process.
Mitigation: To make it better use testing that looks at how well the AI agent works how strong it's what safety measures are in place and have a human review it.
5. Drift after release
When AI agents online they deal with users, data and surroundings that are always changing. This can cause problems. When the AI agents behaviour starts to differ from the plan people lose trust. Teams cannot always say when why or where the change happened.
Mitigation: To reduce the risk always watch the AI agent’s behaviour keep track of changes look at failures and times when help is needed and be ready to go to a previous version of the AI agent. The AI agent must be monitored closely to prevent problems. AI agents, like this need attention to work properly.
6. Poor offboarding and governance closure
The end of the lifespan is also part of a safe AI agent lifecycle. If retired agents still have credentials, related dependencies, or access to systems, the firm is left with extra security risks. Decommissioning, revoking credentials, cleaning up dependencies, and writing documentation are all essential actions in the lifecycle.
Mitigation: think of retirement as a formal process instead than an informal end.
Best Practices for Secure AI Agent Lifecycle Management
One place where AI agent discipline matters most is in the practices teams adopt before problems appear. Here we have listed down best practices that consistently separate well-governed deployments from reactive ones:
- When you start make sure you have a plan for the agent. Write down what the agent is supposed to do how it should behave, what it can and cannot do. This will be your guide for testing and monitoring the agent on.
- Check if the agent behaves correctly. Just because the agent works without errors does not mean it is doing what it should. Create tests to see if the agent does what it is not supposed to do not what it should do.
- Test the agent repeatedly. Every time you make a change test the agent. You cannot just check a thing manually that is not a good way to make sure the agent is working correctly.
- Put the agent in place. Do not turn it on right away. Make sure it is working in the environment then turn it on. This way if something goes wrong you can go back to how things were without disrupting the service.
- See how the agent works normally. After you put the agent in place watch it for a week to see what is normal like how long it takes to do things how often problems come up and how often tasks are completed. If you do not know what is normal you cannot tell if something is going wrong.
- Make sure someone is responsible for the agent at all times. Decide who oversees the agent at each stage. If no one is in charge the agent may not be working correctly. That is a problem with how the agent is managed, which is what we call governance, for the agent.
Real-World Use Cases of AI Agent Lifecycle in Enterprises
In the days agents were mostly used for simple tasks and chat help but now they are used across companies to handle decision-making workflows, system actions and multi-step business processes. Understanding the AI agent lifecycle in theory is one thing. Seeing where it plays out in practice is more useful.
Customer service agents
This is the common use in companies. An agent handles queries. Like order status, booking changes and answers to frequently asked questions. The risk here is that over time the agent starts to rely on humans often than it should which increases support costs and means something in the agent’s decision-making has changed. Keeping an eye on how the agent escalates issues to humans helps catch this problem early.
Financial and transactional agents
Agents that make purchases, process refunds or update records are more critical. Managing the AI agent lifecycle is especially important here. Each agent needs its identity, limited permissions (like autonomous approval below a certain threshold and human approval above it) and a complete record of all actions across every connected system. When these agents are decommissioned, taking away their credentials is not optional.
Internal knowledge agents
Companies use agents trained on documents. Like HR policies, compliance manuals and product specs. The challenge is keeping the agent’s knowledge up to date: when the underlying documents change the agents retrieval layer needs to be updated. The AI agent development lifecycle should include a process for updating the knowledge base when the source content changes, not just when the agents code changes.
Multi-agent orchestration
Companies are increasingly using agents that call agents. This creates a risk: a change in one agent’s behaviour can have unintended effects downstream. Testing environments can't fully replicate how agents interact with each other which means testing each agent alone is not enough. Managing the lifecycle here requires testing scenarios from end to end, across the chain of agents which is referred to as multi- agent orchestration.
Common Challenges in AI Agent Lifecycle Management (And Solutions)
1. Problem
The big problem is that teams work separately. The business team decides what they want to do. The developers build it. The QA team tests it. The IT team makes it work. The security team checks for problems. But no one team sees the picture so issues that start in one stage are not found until much later in another stage.
Solution:
To fix this we need to have a team that includes people from all stages. This team should have leaders at each stage. We need to know who is in charge of making sure everything is okay at each stage. Who says yes to the plan? Who makes sure the tests are good enough before we release it? Who watches to see if there are problems when it is live?
2. Problem
Another problem is that artificial intelligence systems do not always work the way. Traditional testing is based on systems that always work the way.. Artificial intelligence systems can give different answers to the same question. This means that just because a test works once it does not mean it will always work. This is a challenge when we are trying to make sure artificial intelligence systems are working correctly.
Solution:
To solve this problem, we need to change the way we test. If looking for the perfect answer, we should look for answers that are good enough. We should define what a good answer looks like and what a bad answer looks like. Then we should test to see if the system can give us answers. We should also test the system with questions to see if it can handle them.
3. Problem
Another challenge is that artificial intelligence systems can slowly get worse over time. This can happen because of a change in the system an update to the model or a change in how users interact with the system. These changes do not always cause problems, but they can cause problems later. By the time we notice the problem it can be hard to find the cause.
Solution:
To fix this we need to watch the system. We should track how often the system has problems, how steps it takes to complete a task and how long the answers are. These signs can tell us if the system is starting to have problems before the users notice.
4. Problem
We also have a problem with keeping intelligence systems secure. As we use more artificial intelligence systems it gets harder to manage their permissions and access. We need to make sure that each system has its identity and permissions just like a human user. We should also regularly review what each system can do and take away its permissions when it is no longer needed.
Solution:
To solve this problem, we should include intelligence systems in our existing security systems. Each system should have its identity and permissions. We should regularly review what each system can do and take away its permissions when it is no longer needed. We should also make sure to remove the systems permissions when it is decommissioned.
Another challenge is that our testing environments are not, like the world. Our test systems are. Do not have the same variety of data and usage patterns as the live systems. This means that just because a system works in testing it does not mean it will work in the world.
To fix this we should use our testing to make sure the system is probably okay but not to make sure it is perfect. We should release the system to a group of users first and watch closely to see if there are any problems. We should also have a way to roll back the system if something goes wrong. We should not be afraid to use this rollback feature if something unexpected happens.
Don’t wait for drift, failures, or security gaps to surface.
Book a consultation to strengthen your AI agent lifecycleMetrics That Define a Successful AI Agent Lifecycle
Measuring agent performance requires metrics at two levels: operational health and behavioural quality. Here's what to track:
- Task completion rate: What percent of conversations end with the agent completing the users request without needing help from a human? This shows how effective the agent is.
- Escalation rate: How often does the agent pass the conversation to a human? If this rate goes up it might mean the agent is not working as expected or lacks knowledge.
- Topic classification accuracy: Does the agent send requests to the topic or workflow? If not, it can cause problems later.
- Latency per interaction: How long does it take the agent to respond? This affects how users feel. Check it for each type of action. Some integrations are just slower. That’s okay if we know about it. Sudden spikes in latency can mean there are issues with integrations or infrastructure.
- Consumption (cost): This is important for teams that manage AI costs. If token usage goes up without complex tasks it might mean the agents instructions are not efficient or has trouble finding information.
- Guardrail adherence rate: How often does the agent stay within its limits? This is crucial, for security. For the secure AI agent process.
- Feedback and satisfaction scores: Human evaluation is still necessary to check things that automated metrics can't like tone, helpfulness and conversation flow.
Future Trends in AI Agent Lifecycle Management (2026 and Beyond)
By 2026 AI Agent Lifecycle Management will change from test projects to big systems that many people use in companies. The focus will move from using AI as a tool to using AI as a coworker, where computers work together to plan and do tasks. Here are a few things to pay attention to:
- AI Agent Lifecycle Management will get more complicated: Companies are moving from using one AI to using AI systems that work together. This means we need to think about how all these systems affect each other not one at a time.
- Governments will make rules: The EU AI Act, which starts in August 2025 already requires companies to be more responsible with AI and keep track of what AI does. Other countries are making rules. Companies that get ready for these rules now will be off than those that try to catch up later.
- AI will help manage AI: The process of making and using AI will use AI to manage itself. It will group together things that AI does find problems before they happen and suggest ways to make AI better based on what it does. Example: Salesforces Agentforce Optimization feature already does this with something called Moments. It looks at what AI does every week. Finds patterns and ways to improve.
- We will keep track of everything an AI does: The whole history of an AI. What it did what changes were made what happened when it was tested and how well it worked. Will be kept as a record not for people who use the AI but also for people who check that companies are following the rules. AI Agent Lifecycle Management will be very important, for this.
How to Get Started with AI Agent Lifecycle Management
Getting started with AI agent lifecycle management is not about creating a governance plan right away. It is about setting up a foundation from the start so that AI agents can be designed, tested, launched and improved without causing problems later on. If you are just beginning here is a starting point:
- Take stock of your current AI agents: Before you can manage them, you need to know what you have. Write down every AI agent that's already in use what it is for what it connects to and who is responsible for it.
- Choose one AI agent: Go through a detailed review. Write down what it was originally meant to do. Compare that to how it's working now. Check if it has versions if it is being monitored and if there is a clear plan for what to do if something goes wrong. This will show you where your management of AI agents needs to be improved.
- Decide who is in charge before buying any tools: A common mistake is to buy a platform before figuring out who is responsible for what. Set up a plan for who owns what. Who designs, who approves launches, who watches over it. Pick tools that fit that plan.
- Build a testing system early on: The AI agent cycle needs automated testing as a part not something extra. Start with a set of tests add it to your launch process and add more tests as the AI agent changes.
- Think of monitoring as a part of your AI agent: Don't just set up a dashboard. Check it every few months. Assign someone to regularly look at performance numbers set limits that trigger an investigation and create a loop where insights from monitoring help set development priorities.
Building Secure, Scalable, and Trustworthy AI Agents
Enterprise AI fails not because the technology is not ready. It fails because the rules around it are not in place. In this blog post we looked at the five stages of an AI agent’s life. We checked the risks that appear at each stage and the ways to stop them from getting worse when in use. Securing agents must start at the design stage not after they are deployed. A proper approach, to managing the AI agent life gives teams a view, provides accountability and control to put out agents that stay dependable over time. The starting point is simpler than most organizations expect.
Not sure where your agent governance gaps are?
Accelirate offers an AI Agent Lifecycle Assessment as a part of our ROC Model framework that maps your current agent inventory against 5 governance dimensions and identifies the highest-risk gaps in your deployment. Most enterprise teams complete it in a single working session and leave with a prioritised action plan.
FAQs
MLOps focuses on training, deploying, and monitoring machine learning models. The AI agent lifecycle governs how autonomous agents reason, act, and integrate with systems, which requires additional layers of behavioural testing, guardrail enforcement, and identity governance that MLOps frameworks were not designed to handle.
AI agent lifecycle management is the practice of governing an AI agent from the moment it is designed to the moment it is retired. It ensures the agent stays secure, behaves as intended, and remains aligned with business goals as it evolves over time.
Securing the AI agent lifecycle starts at the design stage by defining guardrails, scoping permissions, and establishing what the agent is explicitly not allowed to do. From there it requires continuous monitoring in production, adversarial testing before deployment, and a formal offboarding process when the agent is retired.
The tooling depends on the enterprise stack, but the core needs are an identity governance platform for managing agent credentials and access, an observability layer for monitoring behaviour in production, and an automated testing framework for validating agent behaviour across every update.
The most common failures are intent drift, silent errors in production, and overprivileged access that never gets reviewed. Most of these are preventable by establishing behavioural baselines early, running regression tests after every change, and treating access reviews as a scheduled operational task rather than a onetime setup activity.
The foundation is standardization. Enterprises that scale well apply consistent lifecycle governance across every agent rather than managing each one differently. This means shared identity governance, centralized monitoring, and reusable testing frameworks that make it practical to oversee dozens of agents without proportionally increasing overhead.


