Document Processing – The White Hart of Straight Through Processing
I often have conversations with customers who have started Intelligent Document Processing projects as a part of their RPA practice, and a common thread that has emerged is a general discontentment with the Straight Through Processing rate of transaction processing. Just to be clear, straight through processing refers to transactions that do not require a human touch. I consistently hear from customers that we are seeing too many documents end up for human validation.
Before I address the underlying issues and possible resolutions, lets outline the various components of a generic automated document processing use case.
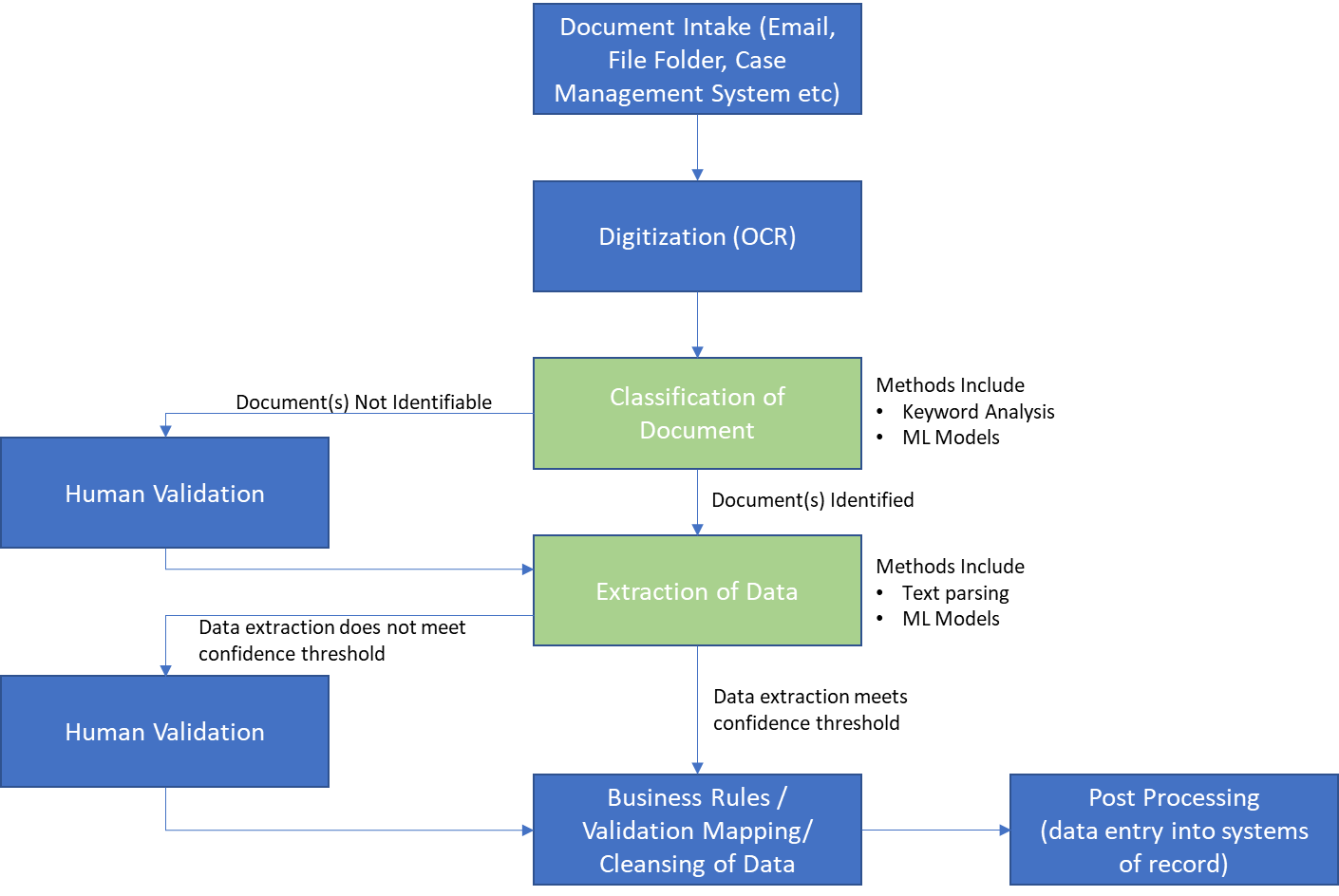
The STP Challenge
A few factors determine whether a document can be processed without any human intervention. I outline these items below and some detail on common challenges
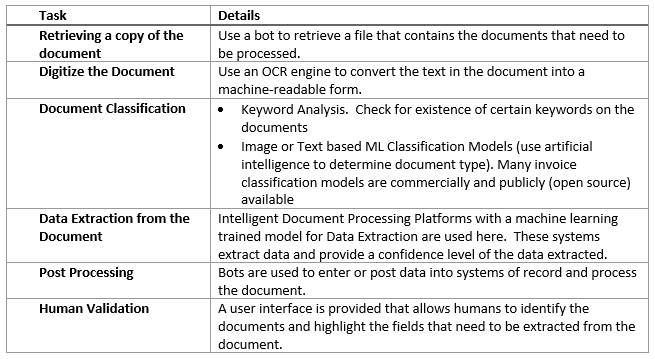
- OCR Quality: OCR engines convert the text on a scanned document to machine readable text. The quality of the incoming document determines the quality of this conversion. Distortions within scanning, stains and blotches on the paper, handwriting on printed text, low quality scans all affect how an OCR engine “reads” the text. Just like a human, OCR engines can make mistakes and identify the letter “o” as a zero or a letter “B” as the number 8.
- Document Classification: For a document to be processed the system needs to understand what type of document is being processed so that the appropriate data extraction model can be used. This is done by either evaluating the text or the images on the document to determine the type of document. This can be done either through traditional programmatic methods or by using a Machine Learning model that is “trained” to classify/identify a document. Multi page documents are always tougher to detect than single page documents. It is almost always advisable to segregate the documents at the intake stage to classify them. For example, all invoices should be received on a separate mailbox than purchase orders.
- Document Data Extraction: Almost all intelligent document processing platforms depend upon a machine learning model that is “trained” on documents to extract data from documents. Training involves a human to identify data elements on a document. The model then uses this data to extract data from a document. The greater the variety of documents the larger the training data set needs to be. Once the model is trained when a document is presented to the model, it returns the extracted data along with an additional parameter referred to as a confidence score. This confidence score is really a “familiarity” score for the extracted data. This is the model’s prediction of its own confidence in the extraction of the data. A confidence threshold is set and any values falling below the threshold require the data extraction to be verified by a human. Note: For document to be processed straight through without human intervention ALL fields on the document must be extracted with a confidence score above the threshold. This can be very challenging if a lot of fields are being extracted. Even a single field with a low confidence score will result in a human needing to look at the document. One way to handle low confidence score extraction is to compare extracted data to an independent source of data if available. E.g., compare the PO number and the vendor’s name on an invoice to a PO number in the accounting system and if they match, the low confidence score can be ignored. As humans validate more documents, the data captured from this validation is then used to “re-train” the model and accuracy of extraction increases over time. The time is dictated by variations in documents and the number of documents being processed through the solution.
- Post Processing Errors: Generally, these errors are related to data consistency between extracted data and the system of record, e.g., Customer Name not found, or product description not matching. These are usually resolved through data cleansing and mapping tables.
As you can see there are quite a few variables that need to line up for straight through processing to occur.
Why the Fuss?
Despite all the challenges i list above, almost all our document processing engagements share a single common metric:
The Human Processing Time Per Transaction Is Almost Always Lower Than The Previously Manual Process, Averaging Between 50-80%.
So, in essence, the business staff was spending less time processing these documents than they were previously. So why the fuss? In my opinion it has a lot to do with expectations from these solutions. When an IDP Platform is pitched with 75-90% accuracy statistic, sales and technical engineers often fail to set the context, especially of the straight through processing percentage. Take a scenario of a document with 10 fields. Every single document processed in this scenario could have 9 out of 10 fields above the threshold (90% accuracy) but 1 required field that is consistently below the threshold would result in 0% straight through processing. Customers often equate IDP accuracy to percentage of documents not requiring human validation.
Business leaders hear “straight through processing” whenever “automation” of the process is promised. This leads to business planning that reduces resources from document processing and assigns them to other tasks. When the business sees a lot of human touch to these documents it impacts this resource planning and results in general displeasure of the implementation. We have seen significant technical efforts being made to increase this STP percentage with mixed results. The reality is that this 50-80% efficiency would not be possible without the implementation of an intelligent document processing platform.
Technical implementation Teams must advise the business of the Intelligent Document Processing paradigm and set the expectations that there may be a significant percentage of documents that may require human validation.
Know Your Why
Identification of the primary value proposition for the automation needs to be front and center when designing the automation. If the main goal of the automation is to reduce the end to end processing time (Average Handle Time) of a transaction, then straight through processing is much more relevant and the solution needs to incorporate this consideration in the design. This will require thorough testing and evaluation of document types and formats. This may also require a rethink of the business process itself.
However, if the focus is on overall reduction of manual labor and human time spent on the transaction then the solution may be designed differently. A significant reduction in human time spent on the transaction can be reduced by implementing data entry and validation rules in the automation logic after the data has been extracted. We find that 50-70% of human time is spent on data entry, validation and other mechanical tasks such as uploading/downloading documents, emailing status of the transaction etc. So abstracting the data validation from the other tasks that can be performed by a bot can result in significant time savings. Over time, this efficiency will increase due to retraining of the ML Models making the classification and data extraction more accurate.