Wouldn’t it be great if software could take the hassle out of document processing? UiPath Document Understanding makes this a reality by automating time-consuming tasks like extracting, interpreting, and processing data from PDFs, images, and even handwritten forms. On average, office employees spend up to 60% of their day working with documents. This leads to repetitive manual routines that distract from higher-priority work.
Businesses may remove a large portion of that burden using UiPath Documentation. In fact, companies using this solution report cost savings of up to 35% and a 52% reduction in document handling errors. By combining automation and artificial intelligence, our solution enables teams to focus on what truly matters rather than becoming bogged down in paperwork.
What is UiPath Document Understanding?

A powerful automation tool called UiPath Document Understanding was created to process a wide range of documents, including PDFs, handwritten notes, scans, and photos, in an intelligent manner. Software robots can extract, interpret, and process data from documents with high accuracy and dependability thanks to the combination of robotic process automation (RPA), optical character recognition (OCR), machine learning (ML), and artificial intelligence (AI).
This tool provides the choice of pre-trained machine learning models for common document categories or custom-train models utilizing UiPath's AI Center. It helps businesses automate tedious document procedures, such contracts and invoicing, which lowers costs, errors, and manual labor while boosting productivity.
Ready to simplify document handling?
Get in Touch with Us Today!Benefits of UiPath Document Understanding
UiPath Document Understanding makes managing documents a whole lot easier. Here’s how it can help:

1. Improved Efficiency
UiPath guarantees that activities are finished considerably more quickly and precisely than manual labor by automated document processing. This implies that workers devote more time to tasks that advance the company's expansion and less time to tiresome paperwork. The majority of paper chores are completed by robots, freeing up human resources for strategic work.
2. Fully Automated Workflows
One of the biggest advantages is that it allows workflows to run automatically, without constant monitoring. UiPath can handle large volumes of documents around the clock, 24/7, which means processes continue even after hours. This reduces delays and keeps everything running smoothly with minimal oversight.
3. Reduced Expenses of Operations
Not only does automate document handling save time, but it also saves money. According to research, employing intelligent document processing can result in a 25–40% cost reduction. Furthermore, businesses usually see a payback period of only 12 months and a 250% return on investment over three years. This implies that companies can reap the long-term benefits of cost reductions while promptly recouping their investment.
4. A Better Experience for Customers
Quicker responses to consumer questions result from faster AI document processing, which enhances overall service. Businesses may respond more quickly, improve customer satisfaction, and maintain operational agility by automating these tasks.
5. Happier Employees
Nobody wants to deal with paperwork. By eliminating monotonous, repetitive chores, UiPath allows workers to concentrate on more important work. As workers work on projects that call for creativity and judgment, this not only raises morale but also increases productivity overall.
6. A Lower Chance of Mistakes
When handling vast amounts of papers by hand, human error is always a possibility. However, UiPath significantly lowers that danger. Over time, the tool's machine learning capabilities increase accuracy, guaranteeing that documents—whether they be contracts, invoices, or HR forms—are handled consistently and accurately.
Steps to Get Started with UiPath Document Understanding
Document Understanding has been in a large upward trend as organizations with automations are looking to enhance their current processes, and others are looking to dive into digital transformation headfirst. UiPath, one of the largest RPA platforms in the market, has a Document Understanding software designed to help build and deploy processes seamlessly by integrating UiPath Document Processing with RPA. With multiple out of the box templates and an easy-to-use interface that allows custom model training, UiPath’s Document Understanding platform is easy to use and quick to deploy. Let’s breakdown getting started with Document Understanding in 5 easy steps.
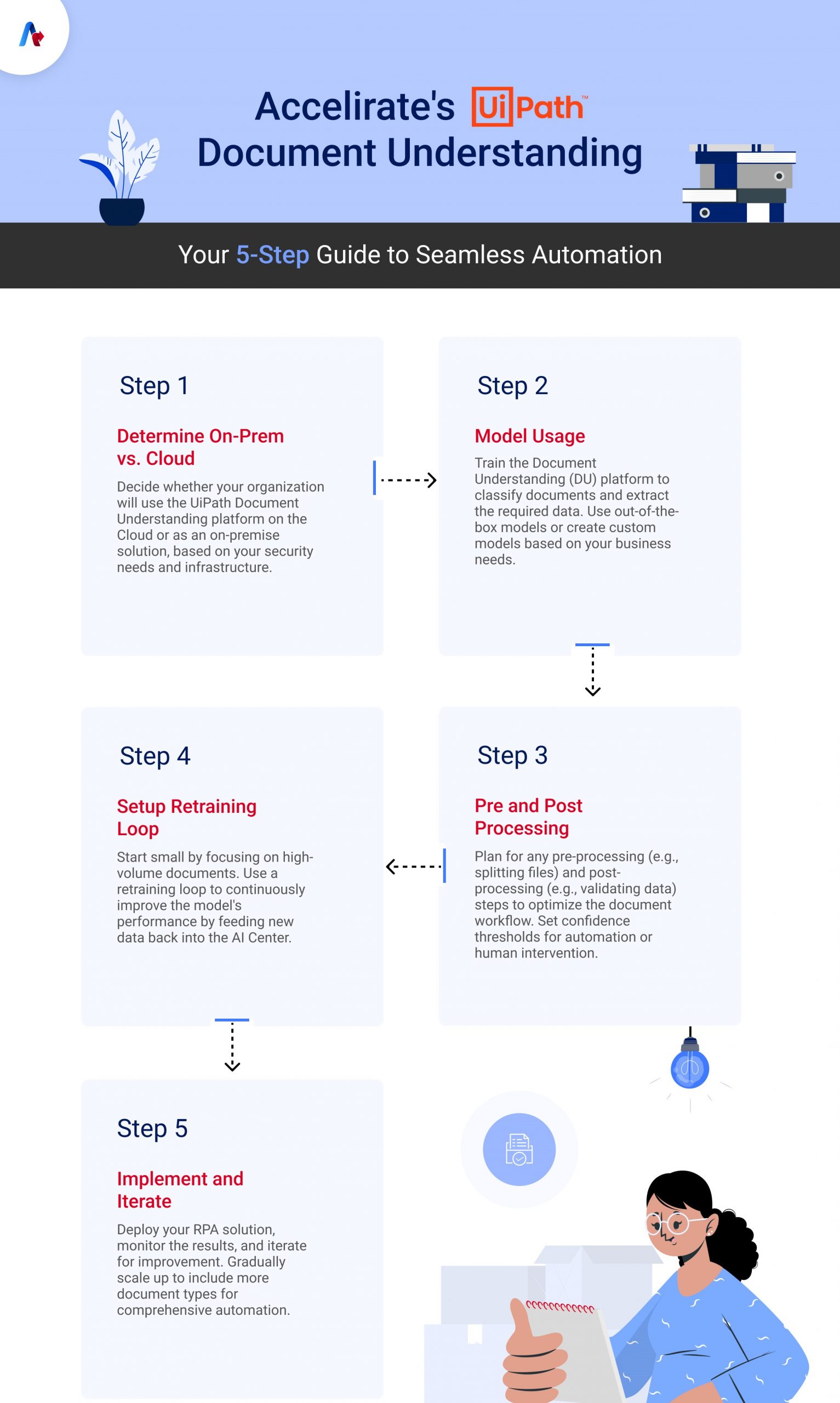
1. Determine On-Prem Vs. Cloud
The Document Understanding Platform is available on both UiPath Cloud and as an on-prem install. Depending on enterprise security guidelines and the types of documents to be processed it may be possible to for an organization to utilize the Cloud Platform. Keep in mind that if opting for the on-prem version of the Document Understanding Platform it requires that the UiPath Orchestrator be at 2020.x version or newer. If you have a prior version, you may be able to use a hybrid model, as there are separate license requirements for each DU model. The first step in implementing Document Understanding Solutions is determining whether the new purchase of licenses may be required and whether your organization would like to host the process on-prem for security purposes or on the Cloud to save storage and infrastructure bandwidth. Once the COE or IT has decided where to host the platform, the DU process can begin.
2. Model Usage
The DU Platform utilizes machine learning models to classify documents and extract data. The organization must determine the source of the desired processes documents and whether the documents can be pre classified based on source or any of the other traditional methods (file name pattern matching, text matching, etc.). If not, then classification is required to be done by DU. With Document Understanding, the model/bot needs to determine how to read and classify the data when it is extracted for the process. The developer for the process will classify the data during development and can leverage the tool during this phase to accurately classify the data.
Next, it’s important to define, data model, and document all the data items that need to be extracted from the incoming documents. UiPath provides many out-of-the-box models that can be used as a starting point for many common business documents. A current list of these models can be found here. If any custom fields need to be extracted, they will need to be labelled. Collecting a sufficient sample of documents to train the model is a necessary step at this time. Generally, 100 or more documents are recommended for best results.
Make sure to have a good distribution of document formats in the training sample. A skewed sample (more documents of just one type) may result in an inaccurate model training. As a best practice, 20% of the documents should be marked as the test set. Label these documents in the Data Manager tool provided within AI Center to train the model. The training results also generate evaluation metrics which will allow you to determine the accuracy of your model before deployment.
Typically, the original business process will tell you what you need to extract. For example, with entering invoices into SAP there are specific pieces of information the SAP system requires to be entered to complete the process such as vendor name, invoice date, amount, etc. Based on the goal of the overall automation the process SMEs (or applications involved as aforementioned) will know what specific information the output of the DU step must be.
At this point it is also important to note that sometimes there are opportunities to extract more data and make the process more efficient and easier from a statistical point of view. To clarify, there may be more information on the document that is of value, with DU it is quick to extract information, so it is beneficial to be on the lookout for other items on the form that the solution can be trained to extract as well. For example, using the same invoice to SAP process mentioned above, if an invoice happens to be itemized, saying what products were purchased, it is an easy addition to train the model to extract item names, SKUs, quantities, and any other information available on the invoice.
Curious how UiPath can transform your document processes?
Talk to Our Experts Today!3. Pre and Post Processing
The next step to implementing a Document Understanding solution is determining what pre-processing and post processing is needed for the process. Pre-Processing steps may include splitting files or collecting additional meta data about the transaction or document being processed. Post Processing refers to actions performed by the automation once the document has been processed by the DU platform and the data has been extracted. The data extracted by the DU platform returns not only the values extracted from the document but also a confidence score for the extracted value. This confidence score can be used within the automation to determine whether the transaction can be processed straight through, or if it needs human intervention.
For most processes that do not have a step to independently verify the extracted values, the confidence threshold for straight through processing is set high (>90%). For others, where extracted values can be verified against other known values, this threshold can be set lower, as there are other checks in place to ensure the accuracy. For example, if the total of an invoice can be validated against a PO total in the system, then a low confidence threshold can be set for the invoice total amount and the invoice in question can be sent to the human for correction if the automation finds that the totals between the invoice and PO do not match.
4. Setup retraining loop
It is always a good idea to start small and scale up. A best practice for getting started with DU is to pick the most desired and most frequently encountered documents and focus there first. Once the solution is implemented, then you can add more document types and scale the DU solution to a larger range of documents.
Typically, we recommend picking something similar to selecting the top 20 vendors with the highest volume of documents submitted. From here the organization should deploy the solution with the starting model trained on those documents and iterate over and over in order to iron out kinks. Once the DU solution is running smoothly and the stakeholders are happy with the results, the organization can add in more document variations for the solution to process. This is done by adding a retraining loop. A retraining loop ensures that human extracted results for documents the model has not yet been trained on are captured and uploaded to the AI Center for the model to be retrained with the new data. This allows for scale as the automation can process more types of documents within the deployed solution.
5. Implement and Iterate
The developers should create the UiPath RPA Solution and use AiFabric to train the machine learning model on the custom document fields for increased accuracy and efficiency. The best practice for this step in the DU solution process is to use logging and other monitoring metrics to measure efficiency and highlight areas for improvement. Once at the deployed stage and desired accuracy metrics, organizations can scale the solution to add more documents and have the automation complete more work.
With Document Understanding organizations can reduce staff time spent on ingesting and extracting information from documents. The automated version of these types of processes is not only faster but far more efficient as bots do not get fatigued and bored causing critical errors as humans would.
Take the Next Step Toward Automation Excellence
Wouldn't it be great if software could take the hassle out of document processing? With UiPath Document Understanding, this is now a reality. By leveraging advanced automation tools such as machine learning, AI, and OCR, businesses can streamline document-related workflows, reduce errors, and free up valuable employee time.
Accelirate, as a platinum UiPath partner, provides expert solutions for implementing Document Understanding into your operations. We help businesses automate the extraction, interpretation, and processing of complex documents such as PDFs, images, and handwritten forms. With Accelirate’s expertise, your team can focus on higher-value work while our solution manages the paperwork. Whether you're processing invoices, contracts, or customer forms, we’ll guide you in seamlessly integrating UiPath Document Understanding for optimal results.


